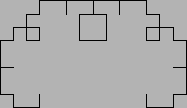
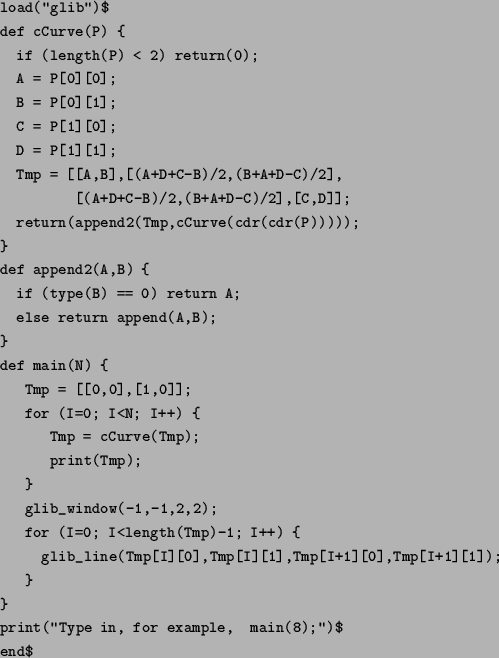
階乗関数の再帰的実装:
def rfactorial(N) {
if (N < 0) error("rfactorial: argument must be 0 or natural numbers.");
if (N == 0) return(1);
else {
return(N*rfactorial(N-1));
}
}
上の関数定義をみればわかるように関数 rfactorial のなかで関数 rfactorial を 呼んでいる.
def xn2(N) {
if (N == 0) return(0);
XN = 2*xn2(N-1)+1;
return(XN);
}
プログラム自体は単純であるが,
実はこのような場面で再帰をもちいるのはあまり得策ではない.
メモリや実行効率の低下があるからである.
8 章で説明した関数呼び出しの仕組みを思いだそう.
関数およびその局所変数は動的に生成, 消滅を繰り返している.
たとえば, 上のプログラムで
xn2(4) をよぶと,
xn2(3), xn2(2), xn2(1), xn2(0)
がつぎつぎとよびだされ, xn2(0) の実行中には,
5 つの xn2 が実行されており,
したがって局所変数 XN および 引数 N も,
それぞれ 5 つ生成されている.
したがって一般に, xn2(n) に対しては,
最大 ![]() 個の変数領域が確保されることになる.
個の変数領域が確保されることになる.
次のようなプログラムを書けば, このようなメモリの無駄使いは 生じない.
def xn2(N) {
XN = 0;
for (I=0; I<N; I++) {
XN = 2*XN+1;
}
return(XN);
}
処理系によっては, このように非効率的に書かれた再帰呼び出しを 自動的に効率的な形式に変更する機能をもったものもある.
def fib(N) {
if (N == 1) return(1);
if (N == 2) return(1);
return(fib(N-1)+fib(N-2));
}
を考える. このプログラムは効率の悪い再帰プログラムである. 理由を述べよ. じっさい良くないプログラムであることを, 再帰を用いないプログラムと比較して確かめよ.
再帰がもっとも強力にその威力を発揮するのは, データ構造自身が再帰的な構造をもっているリスト構造の場合や, 構文解析の場合である. Quick sort なども再帰がその威力を発揮する場合である. これらについては後の節でくわしく考察する. その他, フラクタル (自己相似図形) を描くのも再帰をもちいると 簡単であることがおおい.